Since deep learning models are usually deployed in non-stationary environments, it
is imperative to improve their robustness to out-of-distribution (OOD) data. A com
mon approach to mitigate distribution shift is to regularize internal representations
or predictors learned from in-distribution (ID) data to be domain invariant. Past
studies have primarily learned pairwise invariances, ignoring the intrinsic structure
and high-order dependencies of the data. Unlike machines, humans recognize
objects by first dividing them into major components and then identifying the
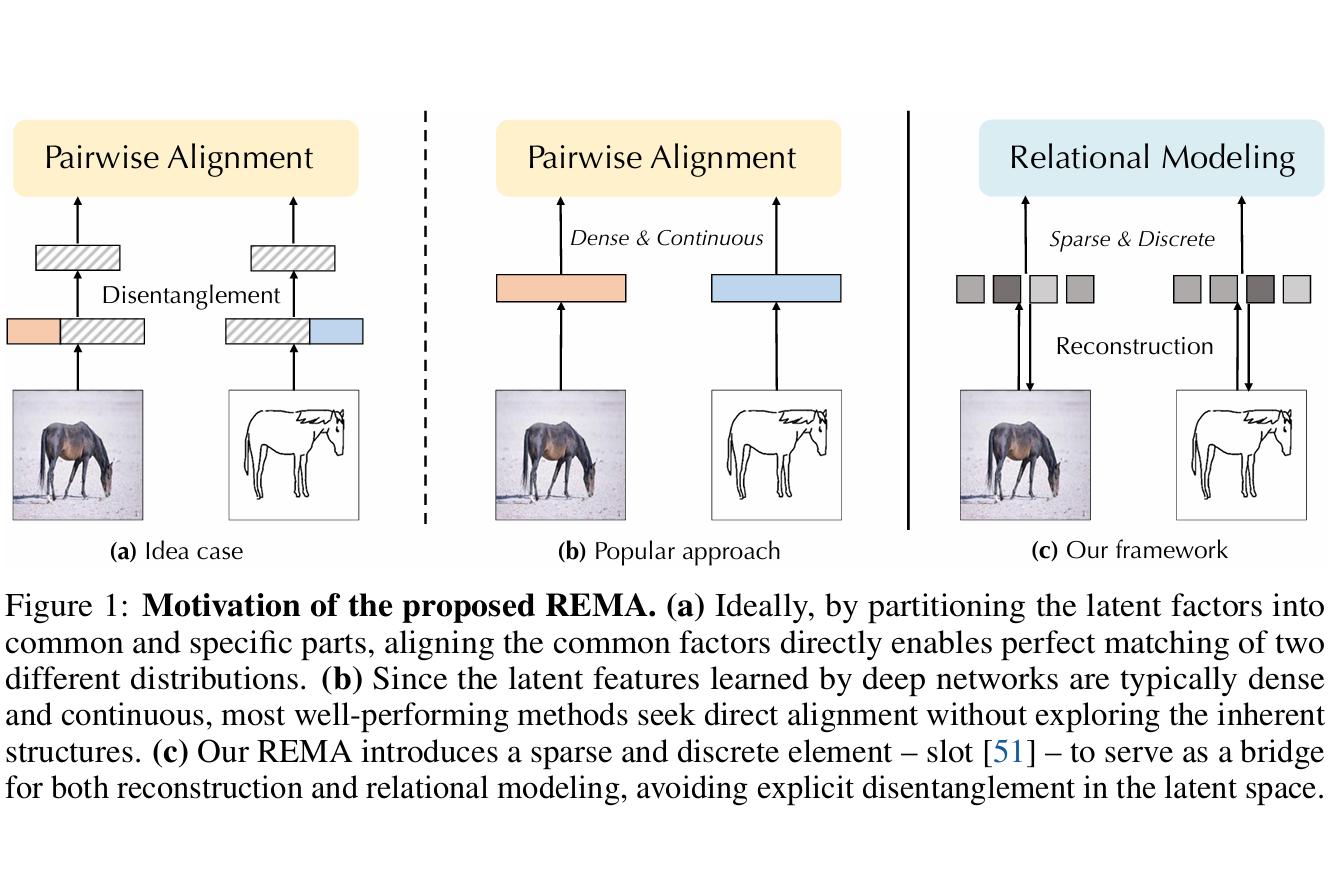
topological relation of these components. Motivated by this, we propose Recon
struct and Match (REMA), a general learning framework for object recognition
tasks to endow deep models with the capability of capturing the topological ho
mogeneity of objects without human prior knowledge or fine-grained annotations.
To identify major components from objects, REMA introduces a selective slot
based reconstruction module to dynamically map dense pixels into a sparse and
discrete set of slot vectors in an unsupervised manner. Then, to model high-order
dependencies among these components, we propose a hypergraph-based relational
reasoning module that models the intricate relations of nodes (slots) with structural
constraints. Experiments on standard benchmarks show that REMA outperforms
state-of-the-art methods in OOD generalization and test-time adaptation settings.
NeurIPS'23
CODA: Generalizing to Open and Unseen Domains with Compaction and Disambiguation
The generalization capability of machine learning systems degenerates notably
when the test distribution drifts from the training distribution. Recently, Domain
Generalization (DG) has been gaining momentum in enabling machine learning
models to generalize to unseen domains. However, most DG methods assume that
training and test data share an identical label space, ignoring the potential unseen
categories in many real-world applications. In this paper, we delve into a more gen
eral but difficult problem termed Open Test-Time DG (OTDG), where both domain
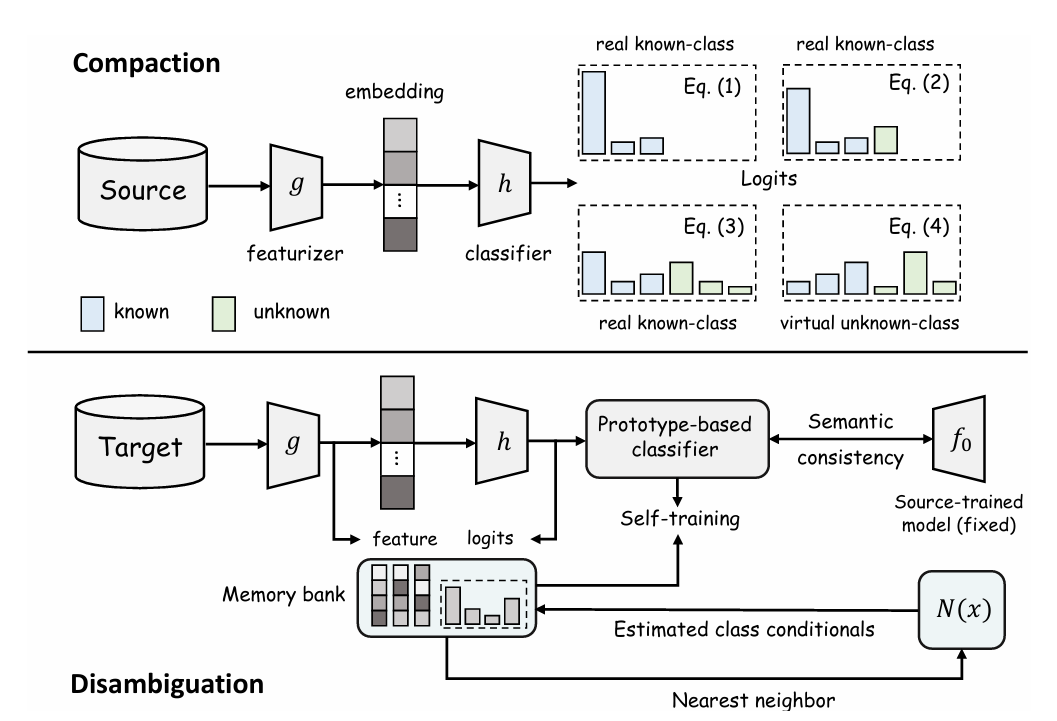
shift and open class may occur on the unseen test data. We propose Compaction
and Disambiguation (CODA), a novel two-stage framework for learning compact
representations and adapting to open classes in the wild. To meaningfully regu
larize the model’s decision boundary, CODA introduces virtual unknown classes
and optimizes a new training objective to insert unknowns into the latent space by
compacting the embedding space of source known classes. To adapt target samples
to the source model, we then disambiguate the decision boundaries between known
and unknown classes with a test-time training objective, mitigating the adaptivity
gap and catastrophic forgetting challenges. Experiments reveal that CODA can
significantly outperform the previous best method on standard DG datasets and
harmonize the classification accuracy between known and unknown classes.
ICCV'23
Activate and Reject: Towards Safe Domain Generalization under Category Shift
Albeit the notable performance on in-domain test points,
it is non-trivial for deep neural networks to attain satis
factory accuracy when deploying in the open world, where
novel domains and object classes often occur. In this pa
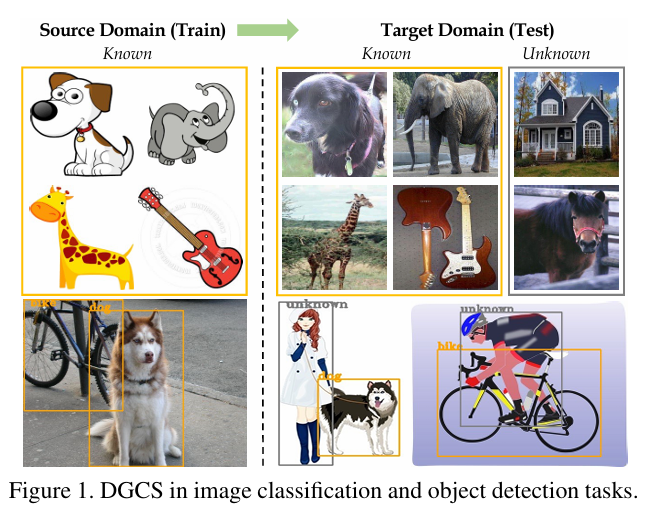
per, we study a practical problem of Domain Generaliza
tion under Category Shift (DGCS), which aims to simulta
neously detect unknown-class samples and classify known
class samples in the target domains. Compared to prior DG
works, we face twonewchallenges: 1) howtolearn the con
cept of “unknown” during training with only source known
class samples, and 2) how to adapt the source-trained
model to unseen environments for safe model deployment.
To this end, we propose a novel Activate and Reject (ART)
framework to reshape the model’s decision boundary to ac
commodate unknown classes and conduct post hoc modifi
cation to further discriminate known and unknown classes
using unlabeled test data. Specifically, during training, we
promote the response to the unknown by optimizing the un
known probability and then smoothing the overall output
to mitigate the overconfidence issue. At test time, we in
troduce a step-wise online adaptation method that predicts
the label by virtue of the cross-domain nearest neighbor
and class prototype information without updating the net
work’s parameters or using threshold-based mechanisms.
Experiments reveal that ART consistently improves the gen
eralization capability of deep networks on different vision
tasks. For image classification, ART improves the H-score
by 6.1% on average compared to the previous best method.
For object detection and semantic segmentation, we estab
lish new benchmarks and achieve competitive performance.
NeurIPS'22
Mix and Reason: Reasoning over Semantic Topology with Data Mixing for Domain
Generalization
Domaingeneralization (DG) enables generalizing a learning machine from multiple
seen source domains to an unseen target one. The general objective of DG methods
is to learn semantic representations that are independent of domain labels, which
is theoretically sound but empirically challenged due to the complex mixture of
common and domain-specific factors. Although disentangling the representations
into two disjoint parts has been gaining momentum in DG, the strong presump
tion over the data limits its efficacy in many real-world scenarios. In this paper,
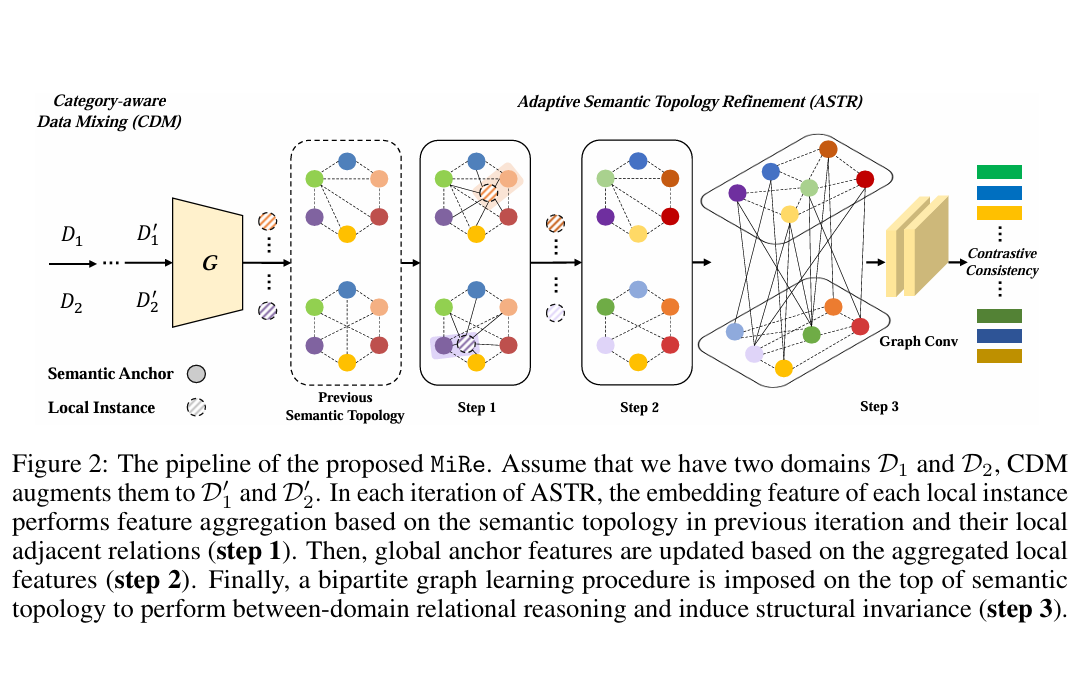
we propose Mix and Reason (MiRe), a new DG framework that learns semantic
representations via enforcing the structural invariance of semantic topology. MiRe
consists of two key components, namely, Category-aware Data Mixing (CDM) and
Adaptive Semantic Topology Refinement (ASTR). CDM mixes two images from
different domains in virtue of activation maps generated by two complementary
classification losses, making the classifier focus on the representations of semantic
objects. ASTR introduces relation graphs to represent semantic topology, which
is progressively refined via the interactions between local feature aggregation and
global cross-domain relational reasoning. Experiments on multiple DG benchmarks
validate the effectiveness and robustness of the proposed MiRe.
Domain Adaptive Object Detection (DAOD) focuses on improving the generalization ability of
object detectors via knowledge transfer. Recent advances in DAOD strive to change the emphasis of
the adaptation process from global to local in virtue of fine-grained feature alignment methods.
However, both the global and local alignment approaches fail to capture the topological relations
among different foreground objects as the explicit dependencies and interactions between and
within domains are neglected. In this case, only seeking one-vs-one alignment does not necessarily
ensure the precise knowledge transfer. Moreover, conventional alignment-based approaches may be
vulnerable to catastrophic overfitting regarding those less transferable regions (e.g.,
backgrounds) due to the accumulation of inaccurate localization results in the target domain. To
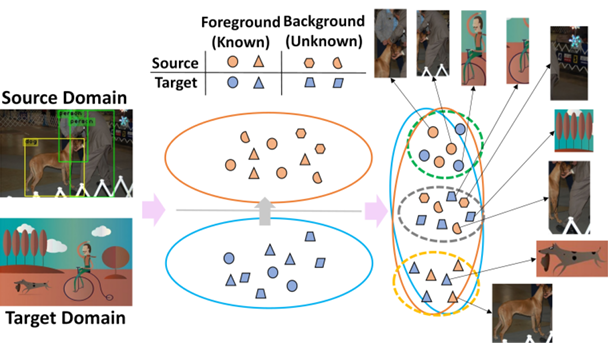
remedy these issues, we first formulate DAOD as an open-set domain adaptation problem, in which
the foregrounds and backgrounds are seen as the “known classes” and “unknown class” respectively.
Accordingly, we propose a new and general framework for DAOD, named Foreground-aware Graph-based
Relational Reasoning (FGRR), which incorporates graph structures into the detection pipeline to
explicitly model the intra- and inter-domain foreground object relations on both pixel and
semantic spaces, thereby endowing the DAOD model with the capability of relational reasoning
beyond the popular alignment-based paradigm. FGRR first identifies the foreground pixels and
regions by searching reliable correspondence and cross-domain similarity regularization
respectively. The inter-domain visual and semantic correlations are hierarchically modeled via
bipartite graph structures, and the intra-domain relations are encoded via graph attention
mechanisms. Through message-passing, each node aggregates semantic and contextual information from
the same and opposite domain to substantially enhance its expressive power. Empirical results
demonstrate that the proposed FGRR exceeds the state-of-the-art performance on four DAOD
benchmarks.
CVPR'22
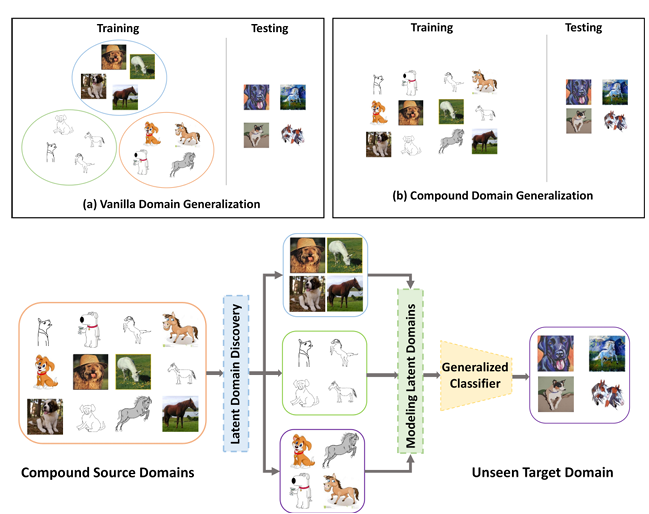
Compound Domain Generalization via Meta-Knowledge Encoding
Domain generalization (DG) aims to improve the generalization performance for an unseen target
domain by using the knowledge of multiple seen source domains. Mainstream DG methods typically
assume that the domain label of each source sample is known a priori, which is challenged to be
satisfied in many real-world applications. In this paper, we study a practical problem of compound
DG, which relaxes the discrete domain assumption to the mixed source domains setting. On the other
hand, current DG algorithms prioritize the focus on semantic invariance across domains
(one-vs-one), while paying less attention to the holistic semantic structure (many-vs-many). Such
holistic semantic structure, referred to as meta-knowledge here, is crucial for learning
generalizable representations. To this end, we present Compound Domain Generalization via
Meta-Knowledge Encoding (COMEN), a general approach to automatically discover and model latent
domains in two steps. Firstly, we introduce Style-induced Domain-specific Normalization (SDNorm)
to re-normalize the multi-modal underlying distributions, thereby dividing the mixture of source
domains into latent clusters. Secondly, we harness the prototype representations, the centroids of
classes, to perform relational modeling in the embedding space with two parallel and complementary
modules, which explicitly encode the semantic structure for the out-of-distribution
generalization. Experiments on four standard DG benchmarks reveal that COMEN exceeds the
state-of-the-art performance without the need of domain supervision.
ICCV'21
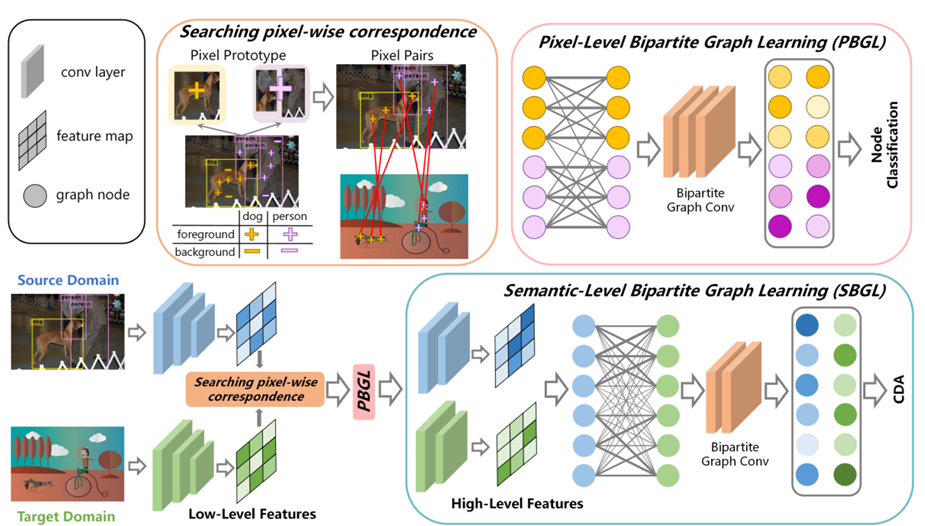
Dual Bipartite Graph Learning: A General Approach for Domain Adaptive Object Detection
Domain Adaptive Object Detection (DAOD) relieves the
reliance on large-scale annotated data by transferring the
knowledge learned from a labeled source domain to a new
unlabeled target domain. Recent DAOD approaches resort
to local feature alignment in virtue of domain adversarial
training in conjunction with the ad-hoc detection pipelines
to achieve feature adaptation. However, these methods are
limited to adapt the specific types of object detectors and
do not explore the cross-domain topological relations. In
this paper, we first formulate DAOD as an open-set domain
adaptation problem in which foregrounds (pixel or region)
can be seen as the “known class”, while backgrounds (pixel
or region) are referred to as the “unknown class”. To this
end, we present a new and general perspective for DAOD
named Dual Bipartite Graph Learning (DBGL), which cap
tures the cross-domain interactions on both pixel-level and
semantic-level via increasing the distinction between fore
grounds and backgrounds and modeling the cross-domain
dependencies among different semantic categories. Exper
iments reveal that the proposed DBGL in conjunction with
one-stage and two-stage detectors exceeds the state-of-the
art performance on standard DAOD benchmarks.
CVPR'21
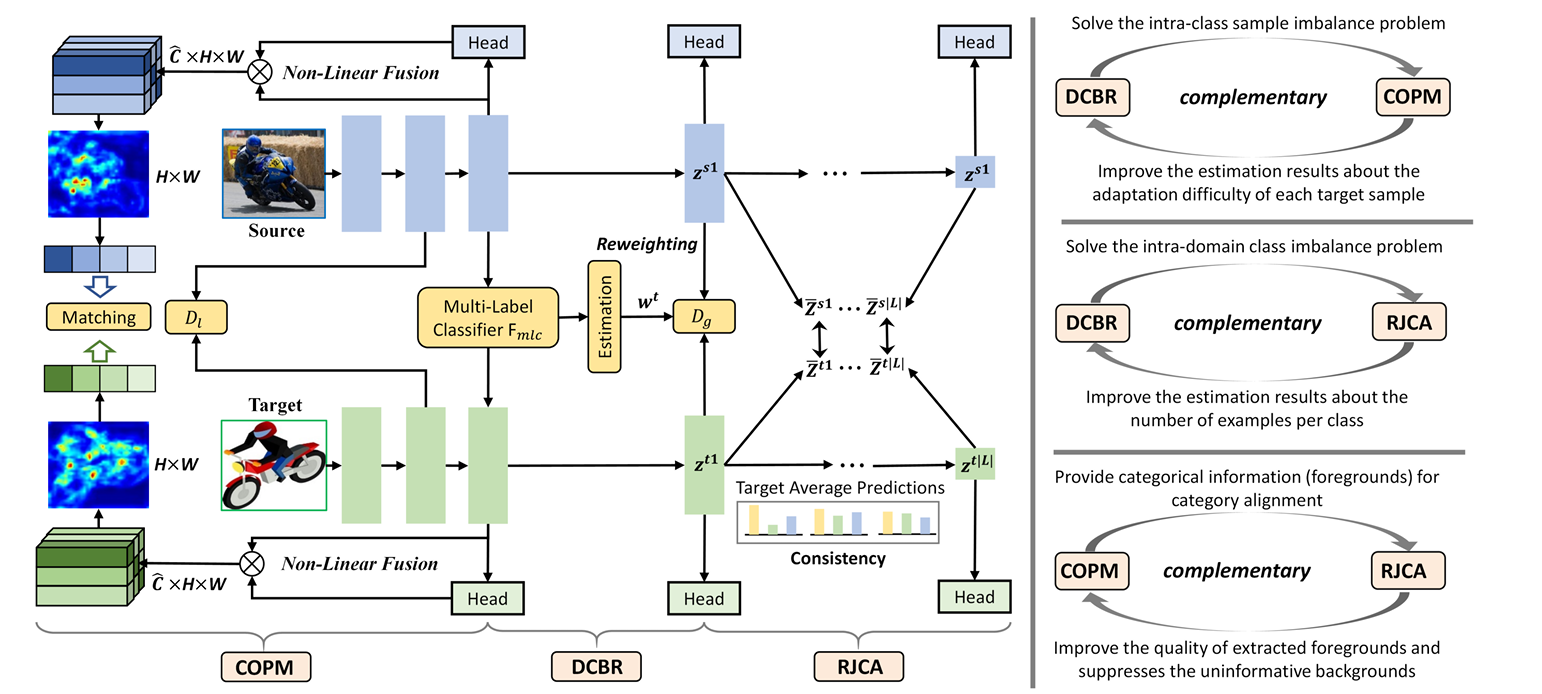
I3Net: Implicit Instance-Invariant Network for Adapting One-Stage Object Detectors
Recent works on two-stage cross-domain detection have
widely explored the local feature patterns to achieve more
accurate adaptation results. These methods heavily rely on
the region proposal mechanisms and ROI-based instance
level features to design fine-grained feature alignment
modules with respect to the foreground objects. How
ever, for one-stage detectors, it is hard or even impossi
ble to obtain explicit instance-level features in the detec
tion pipelines. Motivated by this, we propose an Implicit
Instance-Invariant Network (I3Net), which is tailored for
adapting one-stage detectors and implicitly learns instance
invariant features via exploiting the natural characteristics
of deep features in different layers. Specifically, we facil
itate the adaptation from three aspects: (1) Dynamic and
Class-Balanced Reweighting (DCBR) strategy, which con
siders the coexistence of intra-domain and intra-class vari
ations to assign larger weights to those sample-scarce cate
gories and easy-to-adapt samples; (2) Category-aware Ob
ject Pattern Matching (COPM) module, which boosts the
cross-domain foreground objects matching guided by the
categorical information and suppresses the uninformative
background features; (3) Regularized Joint Category Align
ment (RJCA) module, which jointly enforces the category
alignment at different domain-specific layers with a consis
tency regularization. Experiments reveal that I3Net exceeds
the state-of-the-art performance on benchmark datasets.
CVPR'20
Harmonizing Transferability and Discriminability for Adapting Object Detectors
Recent advances in adaptive object detection have
achieved compelling results in virtue of adversarial feature
adaptation to mitigate the distributional shifts along the de
tection pipeline. Whilst adversarial adaptation significant
ly enhances the transferability of feature representations,
the feature discriminability of object detectors remains less
investigated. Moreover, transferability and discriminabili
ty may come at a contradiction in adversarial adaptation
given the complex combinations of objects and the differ
entiated scene layouts between domains. In this paper, we
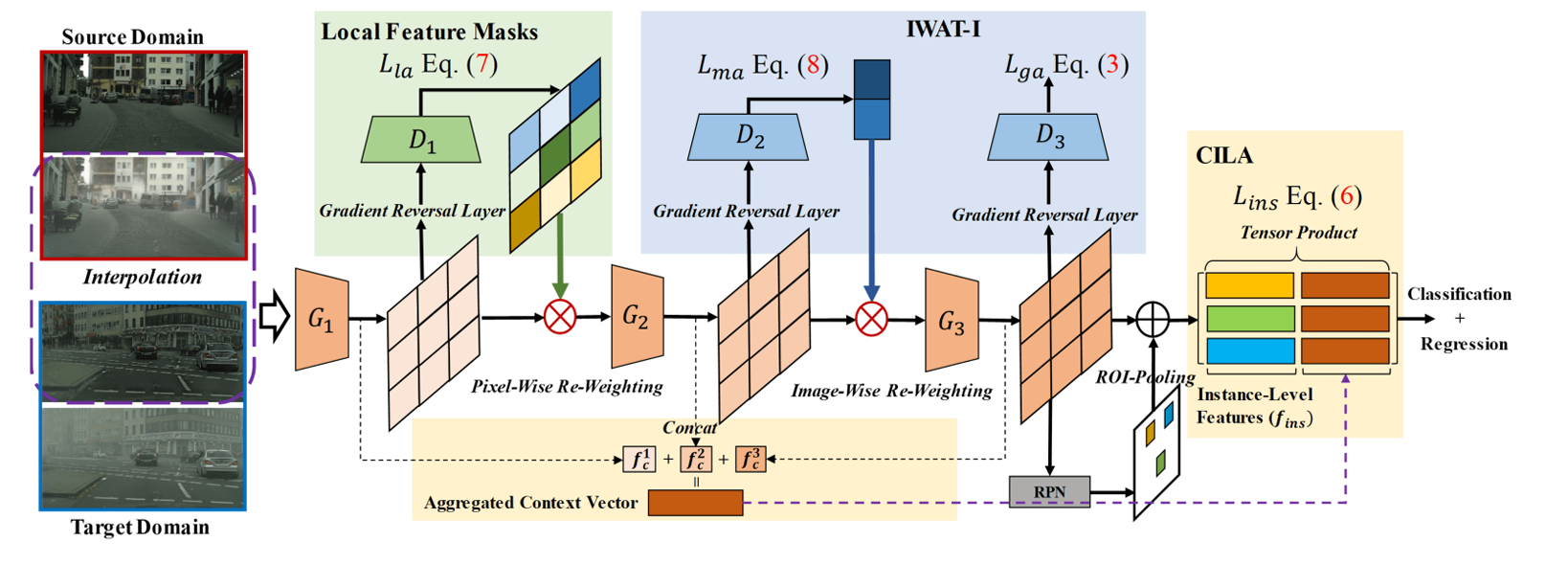
propose a Hierarchical Transferability Calibration Network
(HTCN) that hierarchically (local-region/image/instance)
calibrates the transferability of feature representations for
harmonizing transferability and discriminability. The pro
posed model consists of three components: (1) Impor
tance Weighted Adversarial Training with input Interpola
tion (IWAT-I), which strengthens the global discriminability
by re-weighting the interpolated image-level features; (2)
Context-aware Instance-Level Alignment (CILA) module,
which enhances the local discriminability by capturing the
underlying complementary effect between the instance-level
feature and the global context information for the instance
level feature alignment; (3) local feature masks that cali
brate the local transferability to provide semantic guidance
for the following discriminative pattern alignment. Exper
imental results show that HTCN significantly outperforms
the state-of-the-art methods on benchmark datasets.
CVPR'19
Progressive Feature Alignment for Unsupervised Domain Adaptation
Unsupervised domain adaptation (UDA) transfers
knowledge from a label-rich source domain to a fully
unlabeled target domain. To tackle this task, recent ap
proaches resort to discriminative domain transfer in virtue
of pseudo-labels to enforce the class-level distribution
alignment across the source and target domains. These
methods, however, are vulnerable to the error accumula
tion and thus incapable of preserving cross-domain catego
ry consistency, as the pseudo-labeling accuracy is not guar
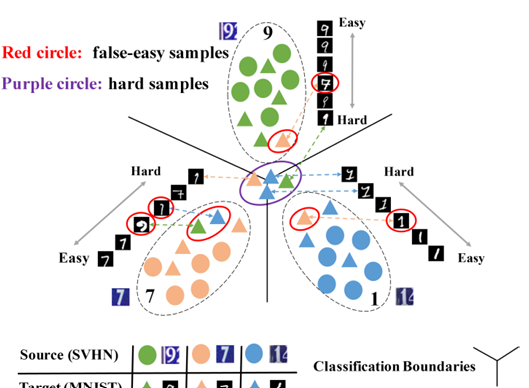
anteed explicitly. In this paper, we propose the Progressive
Feature Alignment Network (PFAN) to align the discrimina
tive features across domains progressively and effectively,
via exploiting the intra-class variation in the target domain.
To be specific, we first develop an Easy-to-Hard Transfer S
trategy (EHTS) and an Adaptive Prototype Alignment (APA)
step to train our model iteratively and alternatively. More
over, upon observing that a good domain adaptation usu
ally requires a non-saturated source classifier, we consider
a simple yet efficient way to retard the convergence speed
of the source classification loss by further involving a tem
perature variate into the soft-max function. The extensive
experimental results reveal that the proposed PFAN exceed
s the state-of-the-art performance on three UDA datasets.